multi-speaker-recognition
Multi-Speaker Recognition and Speaker Specific Question Answering System
Team CryogenX:
- Pratik Varshney (pvarshne@usc.edu)
- Sharvil Kadam (sharvilk@usc.edu)
- Vritvij Kadam (vkadam@usc.edu)
Introduction:
In this project, we have developed a text independent multi-speaker recognition system and speaker specific question answering system. In real world scenarios, we interact with voice assistants which currently responds to queries which are either speaker independent or related to the person who is logged into the system. We aim to make such system more useful by adding a capability to recognize the speaker and respond to queries based on the speaker. The main approaches in area of speaker recognition includes template matching, nearest neighbor, vector quantization, frequency estimation, hidden Markov models, Gaussian mixture models, pattern matching algorithms, neural networks, decision trees, Support Vector Machine (SVM), etc.
The state of the art Speaker Classification and Verification systems use neural networks to achieve 100% classification rate and less than 6% Equal Error Rate, using merely about 1 second and 5 seconds of data (single speaker per data file) respectively [1].
In our system, we have trained a neural network classifier to work for multiple concurrent speakers while providing a limited domain speaker specific question answering system.
What it does:
Multi Speaker Recognition and Limited domain question answering system is an application were people can ask question and get answers specific to their knowledge.
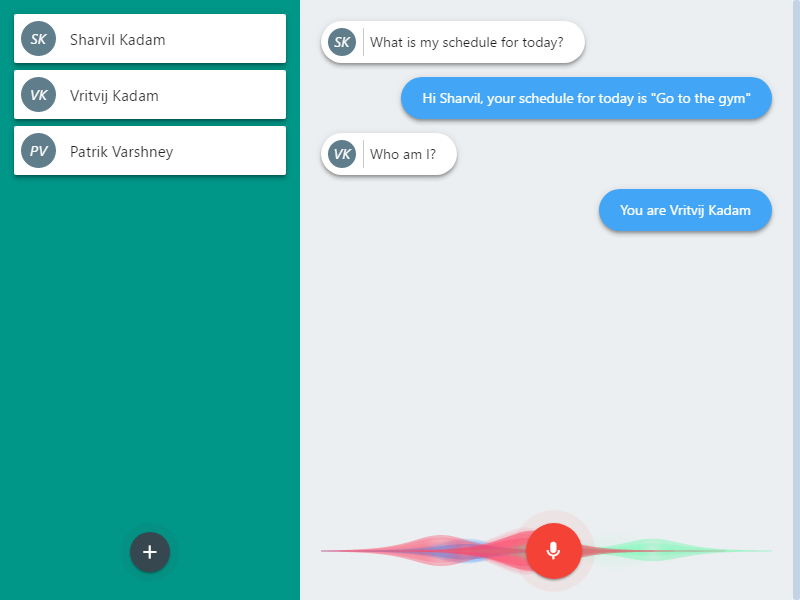
Suppose there are 3 people enrolled in the system A, B, C, (A is a professor, B is a football player and C is a student). Using voice input “B” asks our system “What is my schedule for today?”, the system responds “Hello B, your schedule for today is football practice at 5pm”.
Then later “A” also asks the same system “What is my schedule for today?”, and the system responds “Hello A, your schedule for today is grade midterm exam”. So our system successfully distinguishes between all the enrolled user and interacts with them based on their specific domain knowledge.
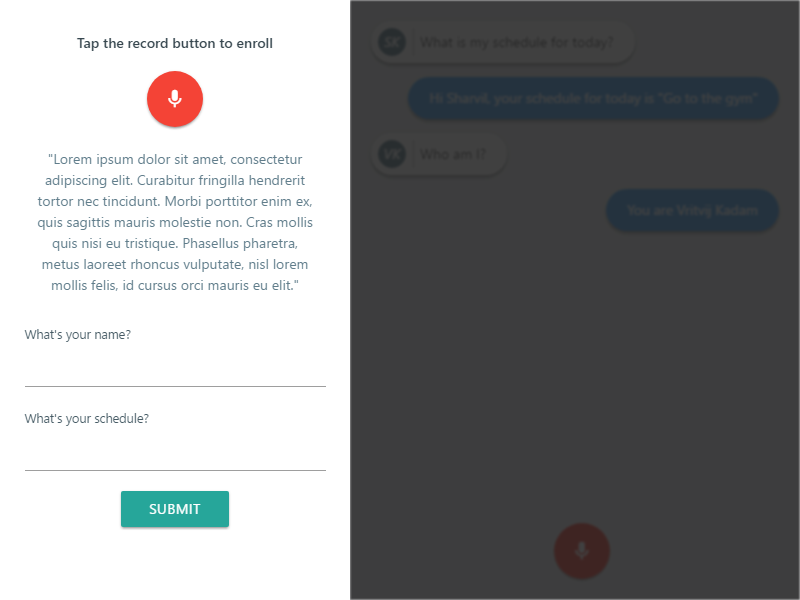
The enrolling process is as simple as recording your voice by reading a paragraph on the UI and answering a few limited domain questions.
UI/UX:
Main Screen:
Enrollment Screen:
How we built it:
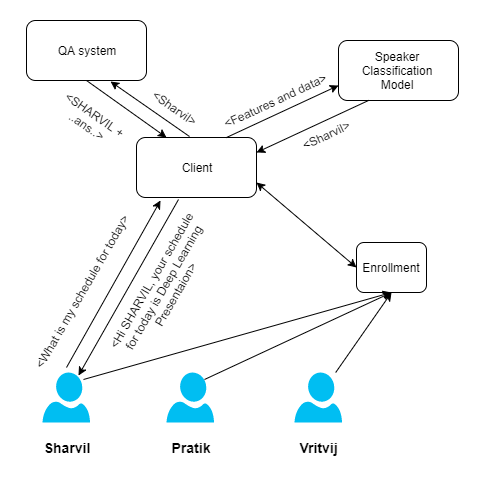
Our system has a speaker classification deep neural network model hosted on the cloud. This model is trained using the data mentioned below. There will be an enrollment module wherein a new speaker can enroll into the system and the neural network will be fine-tuned accordingly. The client is desktop oriented.
Initially we have trained the base model on the TIMIT[2] corpus with 8K sampling rate. Only the first 200 male speakers from the “train” folder are used to train and test the classifier. After creating a satisfiable classifier for speaker recognition using the TIMIT corpus, we then fine-tune the model on our own data consisting of short audio data files (2 to 5 sentences in each) of at least the three members of the team.
For the classification, we record the audio of multiple speakers talking. Then we extract MelFCC features and feed all the data into the model for it to classify. This model will then return a speaker ID for that segment of speech and this ID is passed as a token to the QA system via the client. This limited domain QA system will process it and return the answer appropriate to the speaker.
Architecture:
Timeline:
- STEP 1: We collected the data first. We then built and tested a base model of single speaker classification. This was done in 3-4 weeks because a lot of effort was put into preprocessing the input audio signals, so that the neural network classifies accurately.
- STEP 2: We will then build and test multi-speaker classification model. Tune it to improve accuracy. We then also added an enrollment mechanism, to fine-tune the model. This was done in 3 weeks.
- STEP 3: Lastly, in the last week we built a speaker specific limited domain question answering system. Then we put it all together with an UI.
Detailed steps:
- Collected the audio data TIMIT audio corpus to train our neural network.
- Converted the “.WAV” (Sphere files) inside the TIMIT corpus to standard “.wav” format using a bash script piping the data to the “sph2pipe” program from Sphere Conversion Tool (U-Penn). This simplifies the loading the audio files by using scipy.io.wavfile
- The “.wav” files loaded using scipy.io.wavfile are available as an ndarray, which are then scaled so that the maximum absolute amplitude of the data is 1
- Voice Activity Detection (VAD) was performed to remove the unvoiced parts of the audio file i.e. all the sections of the audio where there is no detected human voice. The output of this algorithm is a list of ndarrays representing the voiced sections in the audio file. The output is tweaked using certain threshold values that are pivotal in tuning the strictness of the trained classifier. To implement VAD we experimented with two methods, WebRTC and our VAD implementation in Python mentioned in the paper by Theodoros Giannakopoulos. Though WebRTC produced better results (98% file level accuracy of classification), it is slow to compute as compared to the python implementation of VAD algorithm. Thus we used our own python implementation of VAD, which produced 92.5% file level accuracy.
- In order to train the network, features are extracted from the segments generated by the VAD. The features are the 39-dimensional Mel-Frequency Cepstral - Coefficients (MFCCs) of these segments using 25ms Hamming windows and 10ms hop time. To compute the MFCC, we experimented with two libraries for VAD, “PLP and RASTA and MFCC” written in Matlab, and “Librosa” written in Python. The MATLAB approach is slightly slower on account of loading the MATLAB engine and running several RPC’s to and from Python to MATLAB for each segment of each file. Both methods produce similar results. Thus we ended up using the Librosa python library for extracting features which is faster.
- The output of the MFCC algorithm is an ndarray having a shape of (39, t), where t is the number of frames. We then concatenated every 100ms of the 39-dimensional feature frames with a hop size of 30ms to obtain an array of 390-dimensional feature frames.
- These frames are then normalized using the global level mean and variance normalization (GMVN). Parameter are extracted from training data set and applied to both test and training data sets.
- The final audio data features are then flushed to the disk to avoid repeated processing.
- The base model used for speaker recognition has an input layer with 390 nodes, a single hidden layer with 200 nodes and an output layer with 200 nodes (corresponding to the number of speakers in the training data that are enrolled). We are using softmax cross-entropy with logits for multiclass classification. We are currently fine tuning our parameters to improve the accuracy of our model.
- Grid search is used to identify the best learning rate. We tried 0.1, 0.5, 0.01, 0.05 … 1e-5 learning rates. The grid search gave us the best learning rate as 0.01 for our model.
- Using 0.01 as the starting learning rate, in our actual model we used adaptive learning rate. The learning rate is tuned by dividing by 5 when it is close to conversion until learning rate reaches 0.000001.
- While training in MATLAB we used Rasmussen’s conjugate gradient algorithm, which handles step size (learning rate) automatically with slope ratio method. However, this implementation is slow to converge and takes several hours to train (around 500 iterations per hour). While training with Python, we used Stochastic gradient descent (SGD) solver which is at least twice as the MATLAB version.
- We then tested the model for multi speaker recognition. The final results were pretty good for classification using this model: Segment level test accuracy is 87%. File level accuracy is 98% using WebRTC VAD and 92.5% using our VAD implementation in Python. Detailed results are explained in the section below.
- The Backend for the limited domain question answering system was built in python using google speech to text API and python nltk to answer speaker specific questions and integrated it with the neural network.
- We then build a simple material design UI/UX for the system (enrollment + speaker classification) and integrated the same to the backend.
Experiments and Results:
The detailed results of some of our experiments for Speaker Classification are as follows:
Matlab Experiments (using Rasmussen’s conjugate gradient algorithm for training):
- Using VAD by Theodoros Giannakopoulos:
-
8K audio sampling rate
Iteration 500
Training Set Accuracy: 0.38316759
Test Set Accuracy: 0.17491915 -
16K audio sampling rate
Iteration 500
Training Set Accuracy: 0.36223822
Test Set Accuracy: 0.22529162
-
Python Experiments (using Stochastic gradient descent for training and 16K audio sampling rate):
- Using WebRTC VAD and static learning rate:
- learning rate = 0.1
Iteration 81, loss = 2.12715560 (Training loss did not improve more than tolerance=0.000100 for two consecutive epochs. So stopped after 81 iterations)
Training set score: 0.404095
Test set score: 0.130363
- learning rate = 0.1
- Using WebRTC VAD and adaptive learning rate (Divide learning rate by 5 when Training loss did not improve more than tolerance=0.000100 for two consecutive epochs till it reaches 0.000001):
-
alpha=1e-3, learning_rate_init=.01 (alpha = L2 penalty or regularization term)
Iteration 150, loss = 1.40940970
Training set score: 0.625305
Test set score: 0.314538
Segment level testing accuracy: 0.864168618267
File level test accuracy: 0.96 -
alpha=5e-4, learning_rate_init=.01
Iteration 60, loss = 1.62085313
Training set score: 0.582599
Test set score: 0.319082
Segment level testing accuracy: 0.88056206089
File level test accuracy: 0.96 -
alpha=1e-4, learning_rate_init=.05
Iteration 500, loss = 1.07831705
Training set score: 0.702429
Test set score: 0.297609
Segment level testing accuracy: 0.873536299766
File level test accuracy: 0.975 -
alpha=1e-4, learning_rate_init=.01
Iteration 344, loss = 1.01685610
Training set score: 0.723204
Test set score: 0.324291
Segment level testing accuracy: 0.873536299766
File level test accuracy: 0.985
-
- Using VAD by Theodoros Giannakopoulos and adaptive learning rate:
-
alpha=1e-3, learning_rate_init=.01
Iteration 499, loss = 0.55597776
Training set score: 0.861235
Test set score: 0.296744 -
alpha=1e-2, learning_rate_init=.01
Iteration 327, loss = 0.82881428
Training set score: 0.835366
Test set score: 0.309380 -
alpha=1e-1, learning_rate_init=.05
Iteration 111, loss = 1.68561857
Training set score: 0.733652
Test set score: 0.349113 -
alpha=0.5, learning_rate_init=.05
Iteration 100, loss = 2.86901901
Training set score: 0.546904
Test set score: 0.349390
Segment level testing accuracy: 0.766331658291
File level test accuracy: 0.925
-
Discussion on results:
Using WebRTC VAD for pre processing data, best results (98.5% file level accuracy for testing data) were obtained with alpha=1e-4 and adaptive learning rate with learning_rate_init=0.01
Similarly, when using VAD by Theodoros Giannakopoulos, best results (92.5% file level accuracy for testing data) were obtained with alpha=0.5 and adaptive learning rate with learning_rate_init=0.05
Challenges we ran into:
- The data preprocessing was the most important step as the features from the audio signal needed to be accurately extracted in order for the neural network to learn.
- Correct parameters for melfcc (parameters affect the quality of the extracted features) and VAD (too high threshold and smoothing == no segments and too low threshold == the entire file as a single segment. Needed fine-tuning and trial and error with multiple algorithms and libraries.
- Data storage: 16K TIMIT data set required 7-9 GB to store the preprocessed data. Hence we had to drop to 8K TIMIT for initial runs.
- The right network and learning algorithm to use to enable enrollment and classification in real-time. Went through at least a hundred configurations of the under-lying algorithm and parameters before we could achieve a satisfactory outcome.
- Reducing training time. Matlab took 6 hours to train. We implemented our system which take less than an hour to train.
What We learned:
- The main goal of this project was to learn how deep neural networks are implemented.
- We also learned new algorithms such as Voice Activity Detection (VAD), feature extraction from audio signals, etc.
- Real time classification of multiple-speakers.
Conclusion:
We achieved 92.5% accuracy for Multi Speaker Recognition for our system. This is achieved by combining the preprocessing components (VAD, normalization, feature extraction) along with the neural network. There is room for improvement in the system to experiment and apply better deep learning algorithm to improve accuracy. Also currently the enrollment process is one person at a time. In the future, we can try to enroll many speakers as a whole. The main objective of the project to classify multiple speakers in real time and answer speaker specific question was achieved.
References:
- TIMIT acoustic-phonetic continuous speech corpus : https://catalog.ldc.upenn.edu/ldc93s1
- Sphere Conversion Tool : https://www.ldc.upenn.edu/language-resources/tools/sphere-conversion-tools
- Neural Network Based Speaker Classification and Verification Systems with Enhanced Features. (2017) : https://arxiv.org/pdf/1702.02289.pdf
- MFCC : https://en.wikipedia.org/wiki/Mel-frequency_cepstrum
- Librosa : https://librosa.github.io/librosa/
- VAD by Theodoros Giannakopoulos, “A method for silence removal and segmentation of speech signals, implemented in Matlab,”
- MATLAB API for Python : https://www.mathworks.com/help/matlab/matlab-engine-for-python.html
- PLP and RASTA (and MFCC, and inversion) in Matlab : http://www.ee.columbia.edu/~dpwe/resources/matlab/rastamat/